
System Design Case Study: Web Crawler
Step1 : Understanding the problem
When we are asked to design any system, the most important thing is to understand what’s the requirement, even a simple system can be interpreted differently by different people, not to mention the complex system.
Let’s assume, the crawler we are asked to design has following requirements:
- it crawls web page for search engine
- it will collect 1 billion pages per month
- it will only crawl and download HTML page
- crawler will de-dup the web pages with same content
Besides, we should pay more attentions on:
- Scalability: web is very large, we need to design a distributed crawler
- Politeness: web crawler should be polite, which means we shouldn’t send too many requests within a short time.
Step2: High Level Design
As far as we know the requirement of crawler, we can prepare a high level design to align with interviewer.
Before that, it’s important to do some “back of envelop estimation”.
- we download 1B web pages per month.
- which means we will handle (1B / (1 month * 30 days * 10^5 seconds)) = around 300 pages per seconds
- assume peak QPS = 500
To design a high level structure, we can start from thinking about the basic algorithm of system, in current case, it should be:
- prepare some seeds URLs
- verify if the URLs has crawled before
- if yes, then discard this URL
- if no, go to step3
- download the content for URLs
- compare the content with existing web pages
- if the page content is existing in our database, then ignore it
- otherwise go to step 5
- store the content into our DB
- pass the downloaded content to link extractor
- link extractor can parse the links from page
- put the extracted URLs into seeds URL pool
then we can draw the flow chart based on above process

Step3 Deep Dive into Design
Now that we figured out the high level design, we may be asked by interviewer to deep dive into some details.
For example, there are several area deserving more discussion:
DFS / BFS
One possible topic is the crawling strategy, it can either be DFS (Depth First Search) or BFS(Broad First Search).
From our high level design, we extract all links from one page then pass it to Seeds URL pools, so our design naturally suitable for BFS.
Besides, we rarely adopt DFS in internet crawler since the depth could be very high, put a lot pressure on local memory.
Politeness
Remember, when we figuring out the requirement, Politeness is very important, if we send too many requests to some website, we put pressures on their server and they may block any request from our IP.
So we need to make sure, for a single host, we only send one request within a time frame.
Solution is, we can ensure only each host/website is only crawled by one worker to avoid extra coordination complex.
To achieve this goal, we can maintain a mapping between hosts and downloader/worker.
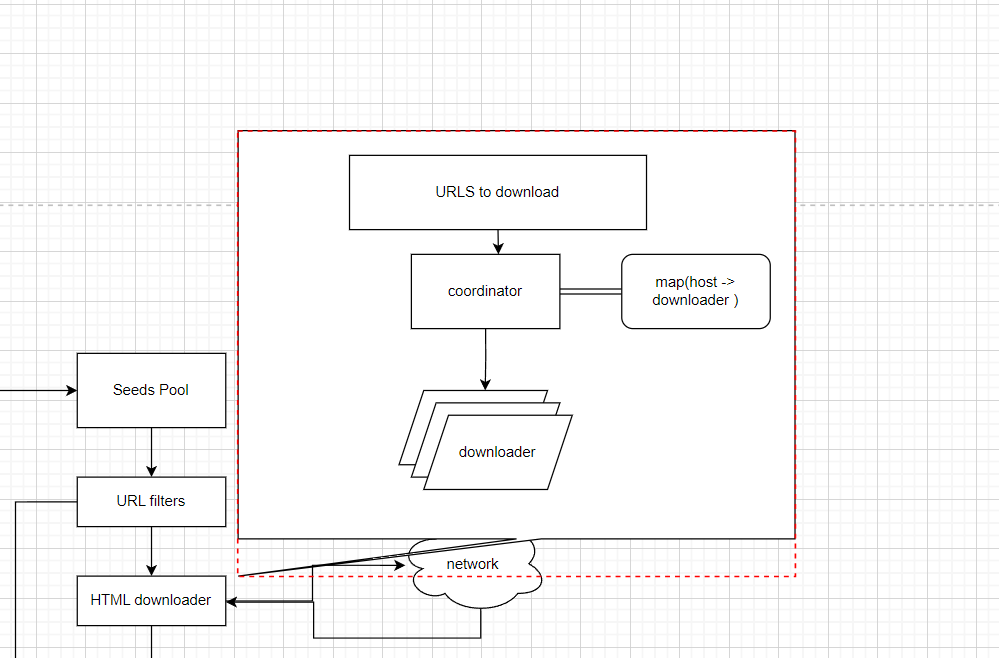
Priority
Different website should have different weights. If there is any update from those most popular website, we want to fetch the content ASAP to make sure our search engine is up-to-dated.
First, when designing the system, we should materialize each feature to achieve “scalability”. So we can introduce a new component here called “Prioritizer” and place before dispatching the URL to downloaders.
In our design, we can prepare different queues for each priority, then based on pre-set priority of different host, we put the URLs into different queues
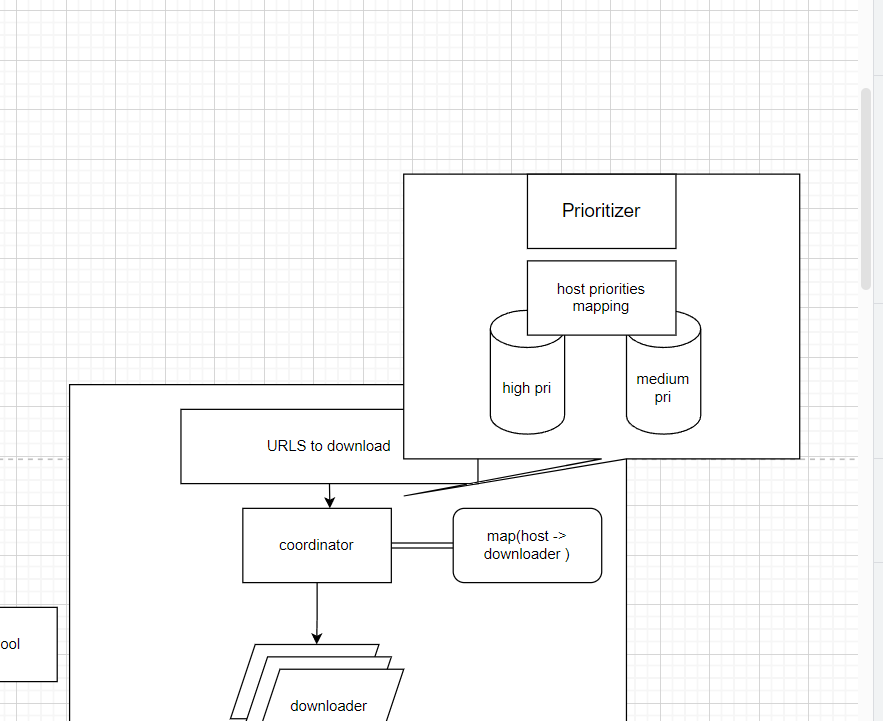
Robustness
To discuss the robustness will demonstrate how professional you are as an engineer.
Distributed System naturally prone to fragile, instead of thinking about a perfect solution, we should think how to recover the system back quickly if it fails.
Some important points to cover:
- we should store the crawl state and data to storage system so that we can resume from that points if system fails.
- we should introduce consistent hashing and sloppy quorum to enable fast rescue from temporary failure.
Step4: Wrap Up
After we complete the main design and discussed some details, at the end of interview we can still come up some interesting topics like:
- Database replication and sharding
- availability, consistency etc.
- analytics: how to design a logging system to monitor the healthiness of system.