
System Design Case Study: TypeAhead System
Type Ahead system can also be called “auto-complete” or “incremental search”system etc.
Step1: Scope the problem
Let’s assume our system will have
- return 5 results as system type each character.
- we assume all search queries have lowercase characters
And what we values most:
- fast response time
- relevant sorted
- scalable
Step2: High Level Design
At the most high level, the system should be broken into two parts:
- Data Gathering: aggregate user’s input in real time
- The basic idea behind Data Gathering is we maintain a frequency table for each input.
- Query Service: respond 5 results based on user’s input
- Basic idea is based on the input, we find the most 5 frequent records from above table and return to user
Step3: Design Deep Dive
High level design give us the basic idea how’s the system looks like.
Now let deep dive into each flow.
Trie
Trie Tree is also called prefix tree etc. here is the wiki page
To be short, it’s a tree-like data stucture which can compactly store strings.
Here are some key features:
- root note represent empty string
- each node stores a character and has 26 children
- each tree node represent a single word
The left part is more like algorithm instead of system design, so I will ignore the left part.
Attention, the optimization part of Trie tree is, on each node ,we maintain one more field storing the most frequent result of that nodes, i.e. top 5 records starting with the nodes.
Data Gathering Service
In high level design part, we mentioned we will maintain a frequency table for user’s input.
It’s common sense that we cannot update this frequency table in real time cause it’s a resource consuming operation.
Instead, we can make it as offline operation which can be performed when server is not busy.
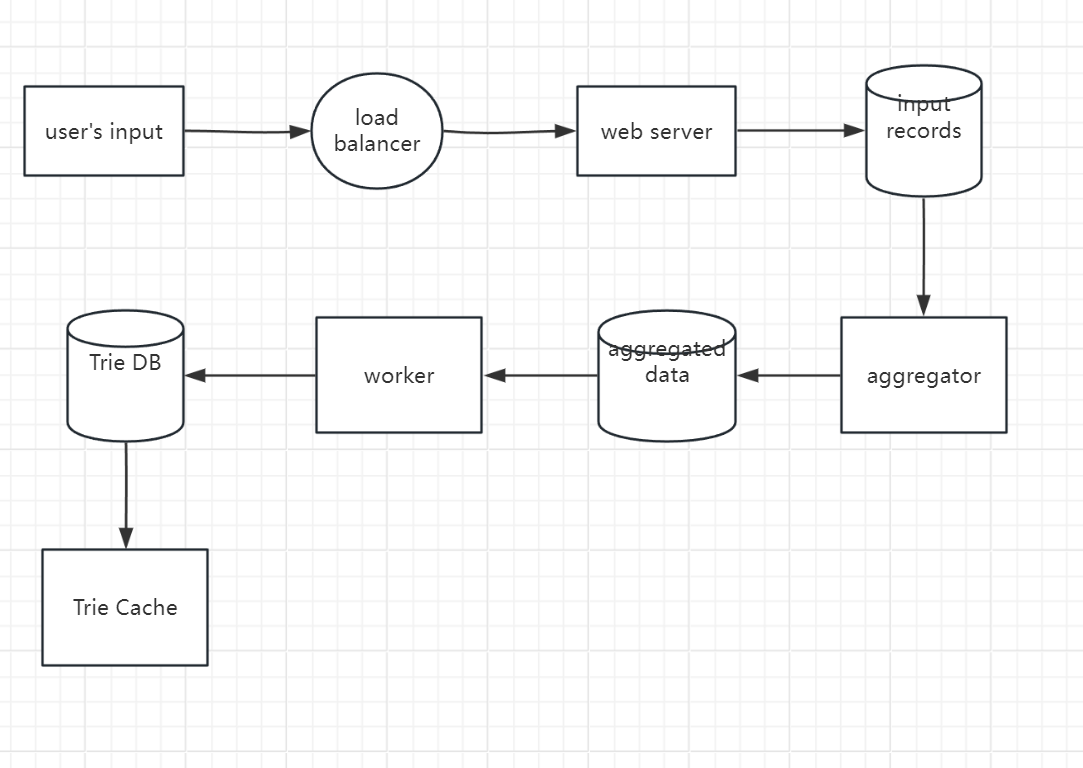
- input records: Store the original input from users
- aggregator: we can do some pre-compute on raw input, then aggregate their frequency based on time period etc.
- workers: set of servers that build the trie data structure and store it in DB
- trie db: since we will periodically build trie tree, we can take a snapshot of it, searilize it and store the serialized data in database. Document DB like MongoDB are good fits for it.
Query Service
From Above chart we can say we store the Trie data in Trie cache.
Then we can get the result from Trie Cache
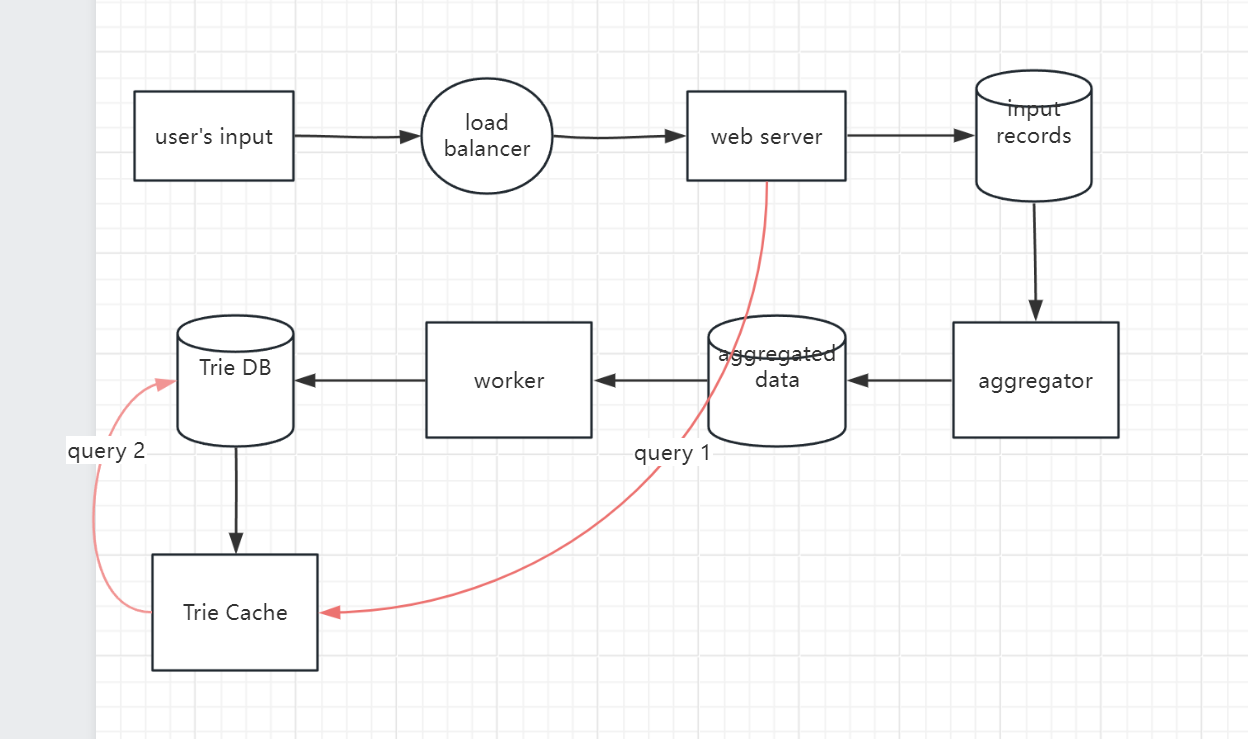
- input will first hit load balancer
- load balancer will direct to web server with light load
- web server first fetch the result from Trie Cache
- if cache don’t have data, then we go to DB to search the result
Scalability
As you can imagine, our app is a storage sensitive app because we need to store a big volume of data.
The easiest sharing way is based on prefix, say the inputs starting with a-h go to server A, the inputs starting with j - q to server b etc.
This sharding need to be done very carefully since some prefix has more results than other prefix.
Step4: Wrap Up
Finally we can discuss the trade-off of design, say
- this design cannot reflect breaking news. since we only periodically update the trie cache
- solution is we can adopt some stream processing like Spark.