
System Design Case Study: Yelp
Yelp is a typical app of “proximity service”, which is used to discover nearby place such as restaurant, hotels etc.
Step1: Scope the problem
Let’s assume we will focus on 3 key features:
- return all business based on users’ location
- business owner can add/delete/update business info, while this don’t need to be reflected in the real time
- customer can view details of business
QPS is around 5K
Step2: High level design
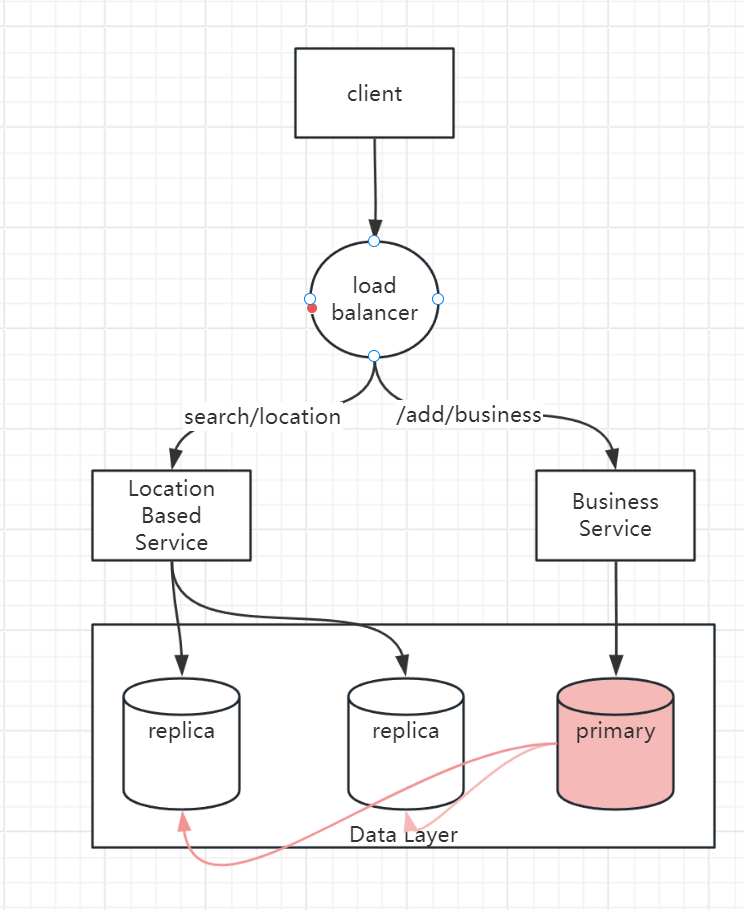
Location Based Service: the core components of system which finds the nearby business for a given radius and location
- it’s a read heavy service with no write request
- QPS is high especially during peak hours in dense area
- this service is stateless so it’s easy to scale up
Database cluster: can use primary-secondary setup. primary database handles all write operations, replicas are used for read operations.
There might be some discrepancy between data read by LBS and data written to primary database.
Overall Flow
- user send a request to query closest restaurants
- load balance forward request to LBS
- Base on user’s location, find its geo-hashed grid
- find the neighbors of the grid
- get all business ids of those grids
- fetch all business info and calculate the distance and other ranking logic, then return the list to client
Step3: Design deep dive
The high level design looks easy, right? Because we abstract and hide the complexity behind each component, let’s focus on Location Based service, where we fetch the nearby business
How to fetch nearby business
In real life, companies might use existing geo database like Geohash, you are not expected to know the internals of those database during an interview. It’s better to demonstrate your problem-solving skills and technical knowledge by explaining how the geo-database index works.
There are several options to fetch nearby business.
option1: two-dimension search
this option can be translated into following pseudo-SQL query:
SELECT business_id, latitude, longitude,
FROM business
WHERE (latitude BETWEEN {:my_lat} - radius AND {:my_lat} + radius) AND
(longitude BETWEEN {:my_long} - radius AND {:my_long} + radius)
We can imagine this process is not sufficient cause we need to scan the whole table.
Even though we can add index, the problem is, the index can only improve search speed on one dimension. So next natural question is, can we map two-dimensional data to one dimension?
The high-level idea is “to divide the map into smaller area and build indexes for fast search”.
option2: geo-hash
it works by reducing the two-dimensional longitude and latitude data into one-dimensional string or letters and digits.
It work by recursively dividing the world into smaller and smaller grids.
Geo-hash usually uses base-32 representation.
option3: Quadtree
A quadtree is a data structure that is commonly used to partition a two-dimensional space by recursively sub-dividing into 4 quadrants until the contents of grids meet certain criteria.
For example, one criterion is keep subdividing until the business inside the grid is no more than 100.
Note, quadtree is in-memory data structure so it’s not a database solution. The data structure is built at server start-up time.
One take away here is, quadtree index doesn’t take too much memory and can easily fit in one server.
After quadtree is built, we can start searching from the root and traverse the tree, until we find the leaf node where the search origin is.
Then find its neighbors until enough business are returned.
operation consideration of quadtree
since we know it may takes some time to build quadtree. here are several consideration for operations
we incrementally update and rebuild the quadtree, a small subset of server at a time.
Scale the database
We have several data type to store
- business table: this can be stored in relational DB and shared based on business id
- geo index table: we can store a K-V pair for each business and its geo-hashed code.
- scale: one common mistake is we quickly jump into sharding schema without considering the actual data size of table. in our case, full dataset of geo index table is not large (quadtree index only takes 1.7G memory)
- so instead of sharding, we can have a series of read replicas to help with read load.
cache?
do we really need a cache layer?
it’s not immediately obvious caching is solid win:
- workload is read-heavy, and the dataset is relatively small. so the query is not I/O bound and they should run as fast as in-memory cache
- if read performance is bottleneck, we can add more DB replicas to improve the read throughput.
The most straightforward cache solution is we can cache the business ids in each geo grids.