
System Design Case Study: Real Time Leaderboard
In this article we will design a real time leaderboard for an online gaming.
Leaderboard is common in gaming and else where to show who is leading the particular tournament.
The leaderboard shows the ranking of the leading competitors and display the position of the user.
Step1: Scope the problem
Here are some key features:
- show top 10 players on the leaderboard
- show user’s specific rank
Step2: High level design
API design
POST /v1/scores
update user’s score when user win a game.
GET /v1/scores
fetch top 10 players from the leaderboard
GET /v1/scores/{user_id}
fetch the rank of specific user
High level architecture
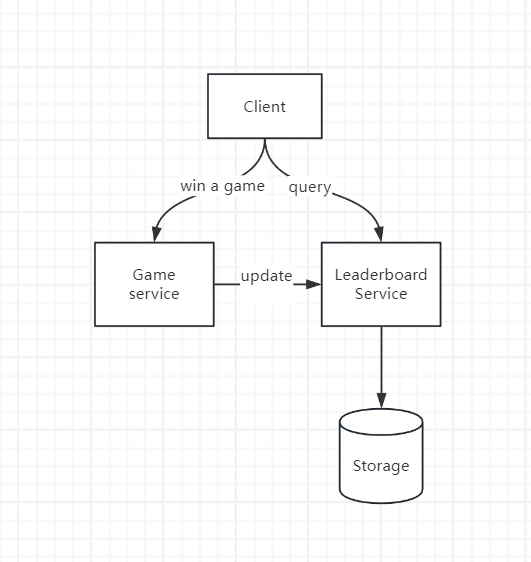
- when a user win a game, send request to game service
- game service validate the game, and calls leaderboard service to update user score
- leaderboard service update user score in storage
- player make a call to leaderboard service to fetch need data.
Question: Do we need message queue between game service and leaderboard service?
This depends on how the score is used.
If it’s used by multiple places, it make sense to put them into message queue and setup different consumers.
Data Model
Storage Solution
SQL DB are not performant when we have to process large amounts of continuously changing information. Attempting to do a ranking operation is time consuming.
How about Redis?
Redis has a specific data type called sorted set that are ideal for solving leaderboard system design.
Each member in sorted set is associated with a score.
Internally, sorted set is implemented by two data structure: hash map and skip list.
Sorted set are more performant than a relational DB because each element is automatically positioned in the right order.
Storage requirement
Let’s calculate the worse scenario where all 25M users has won a game. they all have entries in the leaderboard.
Assume id is 24 character string and score is 16 bit integer. which means we need 26 Bytes for each entry.
26B * 25M ~= 650 MB, any modern server can handle this kind of data volume.
Step3: Design deep dive
Scaling Redis
In previous calculation, we know we can easily store 25M user onto one machine.
But what if we have much more users so that cannot fit into one node?
We need figure out the proper sharding solutions.
Generally speaking there are two category of sharding: fixed sharding and hash sharding
fixed partition
Look at the overall range of points on the leaderboard, we could have 10 shards and each shards have a range of 100 scores.
In this solution, we need to ensure the evenly distribution of scores, otherwise we need to adjust the score range in each shard.
When we query or update user score, we need to know which range the user is.
One thing need to care is when user get more score and we need to move them to another shard.
To fetch the rank of user, we just need to calculate the rank within the current shard and do easy math calculation.
hash partition
Redis cluster provides a way to shard data automatically across multiple Redis nodes.
every key is part of a hash slot.
Hash partition has several limitation:
- when we need to return top K, the latency is high, calculation is time consuming
- doesn’t provide a straightforward to determine the rank of specific user.
Step4: Wrap up
In this chapter we explore how to design a real-time leaderboard for an online game.
We went through API design, Data solution exploration and determine to use Redis sort set as storage solution.
Also we covered the basic flow of update user score in the DB.
Here are some of my takeaways
- one consideration when choose message queue: how to use the message, if we need multiple consumers, then message queue is necessary.
- relational DB is not good at handling large amount of continuously changing data.
- Redis storage requirement calculation
- When sharding the data, fixed partition is more proper than hash partition for ranking-like system