
System Design Case Study: Hotel Reservation System
In this article we will discuss how to design a hotel reservation system, actually this design solution is applicable to all booking-related interview topics, like the flight reservation or movie tickets reservation
Step1: Scope the problem
let’s assume the scale of problem is :
- 5000 hotels
- 1 million rooms
The features we should focus on are:
- show the hotel related page
- show the room related page
- reserve a room
- admin panel to add/remove/update hotel
- support overbooking features
Step2: High level design
Before starting design the architecture, we should do some rough back-to-the-envelope estimation
- we have 5000 hotels and 1M rooms in total
- assume 70% of rooms are reserved and the average stay duration is 3 days
- daily reservation is (1M * 0.7) / 3 ~= 240000, 2.4 * 10^5
- reservation per seconds 2.4 * 10 ^ 5 / 10^5 ~=3.
so we can assume, TPS is 3, which is not high, we can assume QPS is around 300.
API design
post /reservation
the request body can include
{
start_date:"???"
end_date: "???"
hotel_id: "???"
room_id: "???"
reservation_id: "???"
}
reservation_id is used to avoid double booking
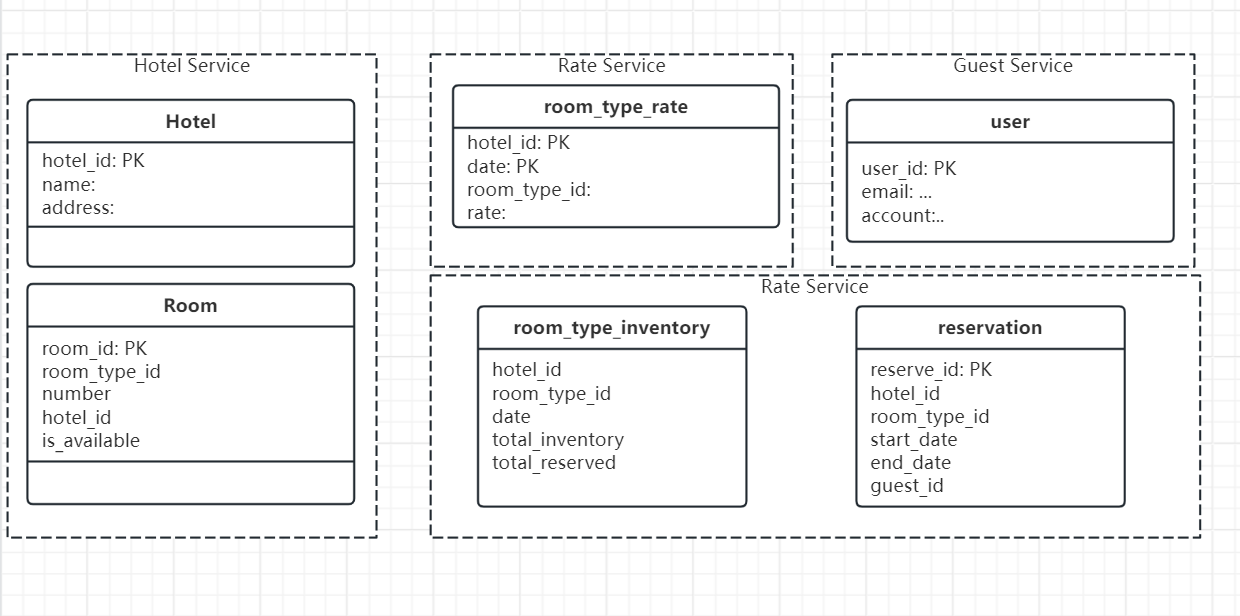
Data Model Design
before we design the data model and choose the DB solution, we need first to look at the data access patterns.
We need to serve following queries:
- view details of a hotel
- find available type of rooms given a date range
- record a reservation
- look up the reservation or past history
We can choose relational DB because:
- relational DB works well with read-heavy and write less frequently workflows. in other words, no-SQL DB are generally optimized for writes
- relational DB provides ACID to help avoid double reservation issues.
- The structure of business data is very clear and the relationships between different entities are stable.
Architecture Design
Let’s try micro-service architecture for this reservation system.
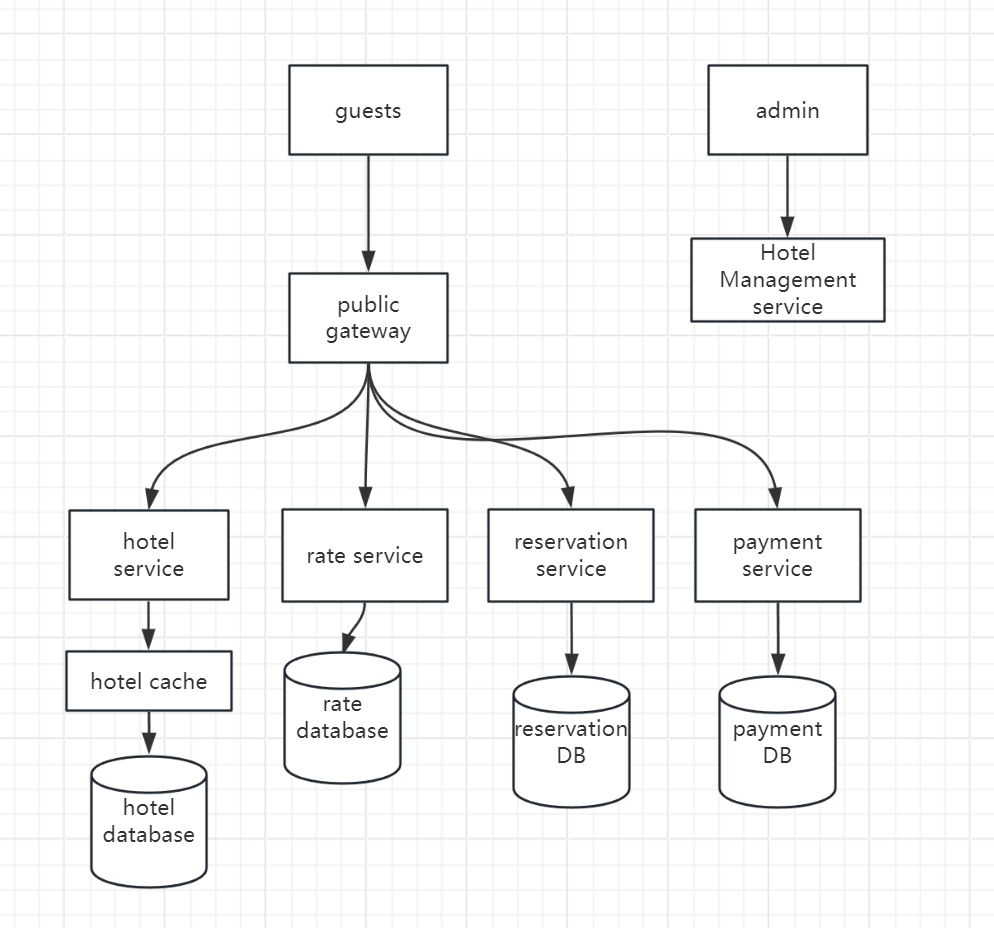
- public API gateway: API gateway is configured to direct requests to specific services on the endpoints.
- hotel service: provides the details of hotels and rooms, since these data are generally static, it can be easily cached
- rate service: provides the room rates for different future dates. The price of a room depends on how full the hotel is.
- reservation service: serve the reservation requests
- payment service: execute payments for customer and update the reservation status
- hotel management service: available for hotel staffs.
Step3: Design deep dive
Improved Data Model
In high level design, we just assume we reserve a room, while in reality, we just reserved a “type” of room, the real room is determined when we check in.
so the body of reservations API should be improved to:
{
start_date:"???"
end_date: "???"
hotel_id: "???"
room_type_id: "???"
reservation_id: "???"
}
From SQL perspective, handling reservation request involves two steps
- check hotel’s availability, how many rooms are still available
- create a new record in reservation table
If the reservation data is too large, we can:
- only store current and future data. historic data can be archived
- sharding: in both query, we need to choose hotel first, so hotel id can be a good sharding key.
Concurrency Issues
Inevitably, we need to solve two problems:
- same user duplicated orders
- multiple user try to book same room at the same time
For question 1, commonly speaking there are two solutions:
- Client side solution: Client can grey out the button to avoid duplicated submit, however user can disable the JS and bypassing client check
- Idempotent API: add an idempotent key in reservation API request. An API call is idempotent if it produces the same result no matter how many times it’s called.
- that’s the reason we put “reservation_id” in the reservation API body.
- when user enter the reservation details and click “continue” button, system will generate the reservation order for user to review. reservation_id is generated and return as part of API response
For question 2, there are following techniques to solve the issue:
- Pessimistic locking
- Optimistic locking / DB Constraints
Pessimistic locking
prevent simultaneous updates by placing a lock on a record as soon as one user start to update it.
But it’s easy to imagine this solution is not scalable, if a transaction locked too long, other transactions cannot access to the resources and be blocked as well.
Optimistic locking / DB Constraints
This approach allows multiple concurrent users to update the same resources.
- A new column called “version” is added to the DB table
- before user modify database, application read the version number of the row
- when user update the row, application increase the version number by 1 and writes it back to DB
- DB validation check if the version number is matched. if not valid, then retry the step 2
this approach also face issues when the concurrency is very high, because the request might be retried multiple times.
Scalability
Let’s evaluate the scalability of our system
-
since we are using micro-service system, each component is stateless, so they are not the bottlenecks of system
-
caching: for reservation service, only current and future hotel inventory data are meaningful.
Besides, the inconsistency between cache and DB doesn’t matter because the DB update will be invalidated due to version mismatch, DB can always invalidate the reservation request.
-
It’s worth noting that addressing data inconsistency between microservices requires some complicated mechanism that greatly increase the complexity of overall design.
Step4: Wrap up
- when should we select relational DB? when we find the system is read heavy and write less
- how to avoid rate duplicated order from same user?
- idempotent API: attach ID to the api call, server will only handle each ID one time.
- how to avoid multiple reservation for same room type from different user?
- add a new column “version” to table.
- when evaluate the availability, check whether each components is stateless or not.