
System Design Case Study: Distributed Message Queue
Message queue provide communication and coordination for those building blocks.
In this chapter, we will design a distributed message queue with additional features, such as long data retention, repeated consumption of message
Step1: Scope the problem
The basic functionality of message queue is straightforward: producer and consumer.
Producer send the message to a queue, and consumer consume messages from it.
Let’s assume, the key features we want to design are:
- producers
- consumers
- messages can be consumed repeatedly
- message size can be KB range
- ability to deliver messages to consumer in the order they were added to the queue
- data delivery semantics
Step2: High level design
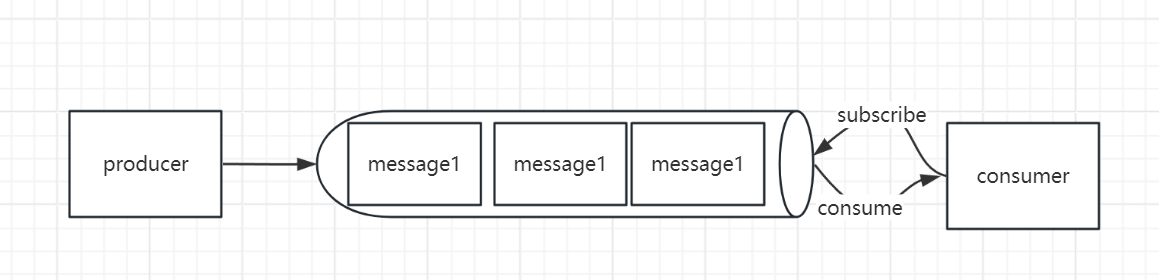
- producer send message to a queue
- consumer subscribe to the queue and consume the subscribed message
- both producer and consumer are treated as client of message queue.
pub-sub messaging model
Let’s introduce a new concept: topic
Topics are the categories used to organize messages. Each topic has a name that is unique across the entire message queue service.
In pub-sub model, a message is sent to a topic, and consumed by consumers who subscribe that topic.
topic, partition and brokers
If topic is too large to be fitted in one machine, we can partition it.
Partitions are evenly distributed across the server in the message queue cluster. The server holds partitions are called Broker
The position of a message in partition is called offset
When consumer subscribe to a topic, it actually subscribe to one or more partitions and pull data from them.
When there are multiple consumers subscribe to a topic, each consumer is responsible for a subset of the partition for the topic.
consumer group
consumer group is a set of consumers, working together to consume messages from topic.
each consumer group can subscrube to multiple topics and maintain its own consuming offsets.
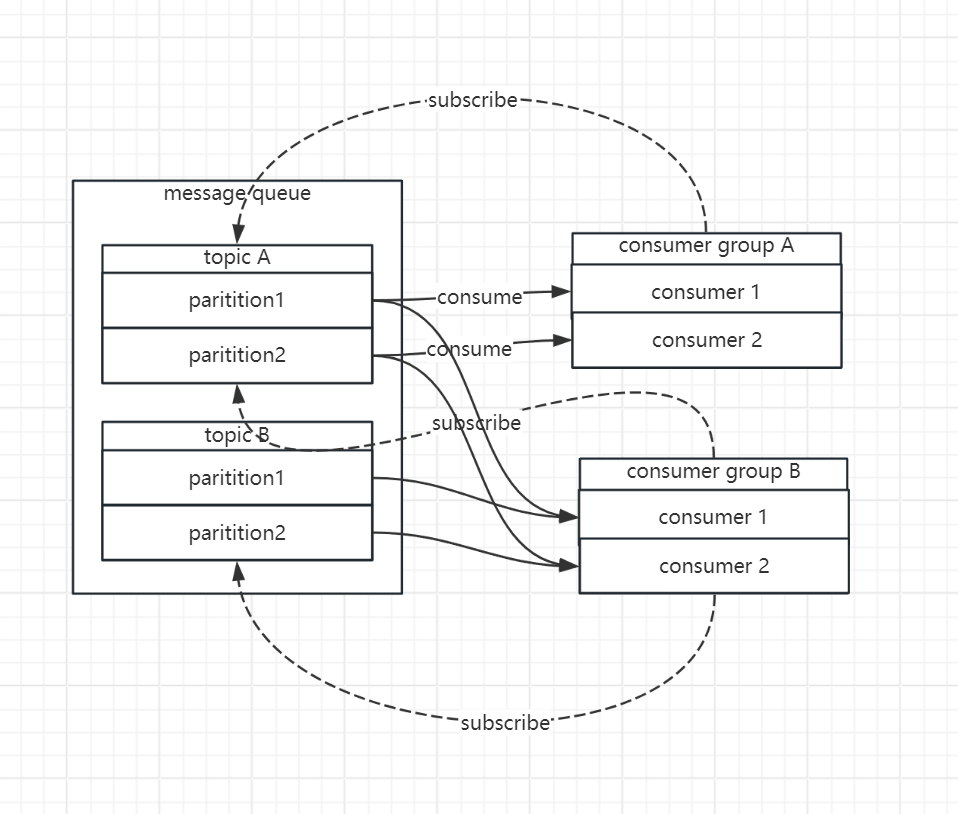
- consumer group A subscribes topic A
- consumer group B subscribes topic A & topic B
- we add a constraint that a single partition can only be consumed by one consumer in same group.
high level architecture
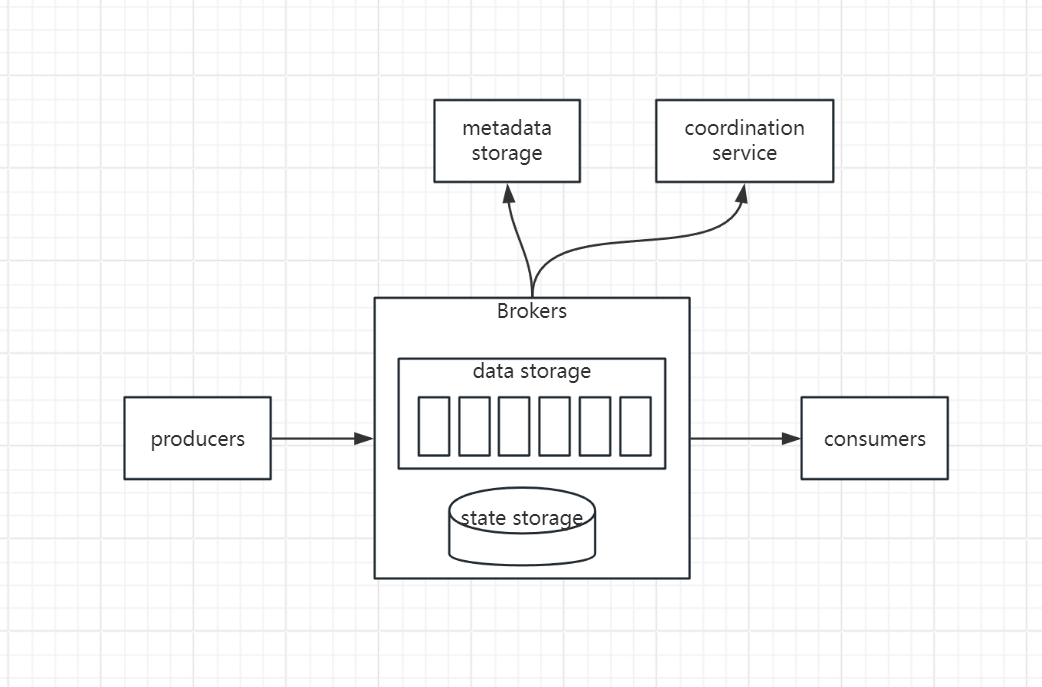
- broker: holds multiple partitions, each partition holds subset of messages of topic
- storage
- data storage: messages are persisted in data storage in paritions
- state storage: consumer state are managed here
- metadata storage: configuration and properties of topics are persisted here.
- coordination service
- service discovery: when brokers are alive
- leader election: one of brokers is selected as the active controller. The active controller will be responsible for assigning partitions
Step3: Design deep dive
Data Storage
First let’s consider the traffic pattern of message queue
- write heavy, read heavy
- no update & delete operation
- sequential read/write access
so the database is not the best option, because it’s hard to design a database that support both write-heavy and read-heavy access pattern.
How about WAL(write ahead log).
It’s just a plain file where new entries are appended to an WAL file.
We will persist message as WAL files on disk. It has pure sequential read/write access pattern. i.e. each partition is a WAL files, and WAL file cannot grow infinitely, we should divide the file into segments, and only have one active segment one time.
Message data structure
It defines the contract between the producers, message queue and consumers.
- message key: used to determine the partition of message
- message value: the payload of message, can be plain text or compressed binary block.
- topic, offset, timestamp etc.
Producer Flow
- Producer sends messages to the routing layer
- router layer reads the replica distribution from metadata storage, route the message to the leader replica of target partition.
- leader replica receive the message, follower replica pulls data from leader
- when “enough” replicas have synchronized the message, the leader commits the data, which means the data can be consumed.
Consumer Flow
Consumer specify its offset in a partition and receives back a chunk of events beginning from that position.
Most message queue choose the pull model.
- a new consumer want to join group 1 and subscribes topic A
- it fins the corresponding broker, which is responsible for coordinate the consumer group
- coordinator confirms that the consumer has joint the group and assign to partition 2
- consumer fetch the message from last consumed offset, which is managed by state storage
- consumer process the messages and commits the offset to the broker
Consumer Rebalancing
- initially, only consumer A is in the group, it consumes all partitions and keeps the heartbeat with coordinator
- consumer B sends a request to join the group
- coordinator notifies all consumers in the group in a passive way, when A’s heartbeat is received, it asks A to rejoin the group
- coordinator choose one of them as the leader and informs all consumer about the election result
- leader consumer generate the partition dispatch plan and send it to the coordinator.
- followers ask the coordinator about the partition dispatch plan
Step4: Wrap Up
Some learnings
-
each topic can have multiple partitions, partition is the basic unit of storage in MQ,
-
partitions can be stored as WAL file, which can be divided into segments
-
partitions can do primary-secondary backup, primary node is responsible for accepting the message from producer, secondary node is consumed by consumer
-
each consumer can only consume one partition, to guarantee the order of consumption
-
each consumer group has its own coordinator, which is responsible for elect the leader
-
leader consumer will dispatch the partitions to each consumer
-
storage design is interesting
- metadata storage to store the configuration of partitions
- state storage to store the consumer’s state information
- data storage to store the partitions, which is WAL