
System Design Case Study: Digital Wallet
In digital wallet servce, user can store money in wallet and spend it later.
It can not only spend money, but can also transfer money to someone else account without charging extra fees.
Step1: Scope the problem
let’s assume the features we are going to implement are:
- support balance transfer between two digital wallets
- support 1M TPS
- support transaction
- support reproducibility
Step2: High level design
API Design
POST /wallet/transfer
from:
to:
amount:
currency:
transaction_id:
In-memory sharding solution
wallet application maintains an account balance for every user account.
We can leverage Redis to store this information. The number of partitions and addresses of all Redis node can be stored in a centralized place.
The problem is, wallet service need to update two Redis node for each transfer, there is no guarantee that both updates would success.
So two updates need to be in a single atomic transaction.
Distributed Transaction
The problem right now is, how do we make the updates to two different storage node atomic?
Distributed transaction is the solution
2-phase commit
In distributed system, a transaction may involve multiple processes on multiple nodes.
- the coordinator performs read and write operations on multiple DB as normal, involved DB will be locked
- when commit the transaction, coordinator ask all DB to prepare the transaction
- coordinator collects replies from all DB and performs:
- if all DB reply yes, coordinator ask all DB to commit the transaction they have received
- if any DB reply no, coordinator ask all DB abort the transaction
The biggest problem of 2PC is it’s not performant, the locks can be held for a long time.
Try-Confirm/Cancel (TCC)
- in first phase, coordinator ask all DB to reserve resources for transaction
- in second phase, coordinator collects reply from all DB:
- if all DB reply yes, coordinator ask all DB to confirm the operation
- if any DB reply no, coordinator ask all DB to cancel the operation.
two phases in TCC are in separate transaction, while the phases in 2PC are wrapped in the same transaction.
So in TCC, what happens when first phase - try, failed?
just revert the transaction performed in first phase.
Phase Status Table
What if the service restarts in the middle of TCC, between first phase and second phase?
When it restarts, all previous operation history might be lost. system may not know how to recover.
The solution is, we store the progress of TCC as phase status in a transaction DB, then we can store this information
Saga
- all operations are ordered in a sequence. each operation is an independent transaction on its own DB
- operations are executed from first to the last.
- When an operation has failed, entire process start roll back, using compensating transactions.
Saga v.s. TCC
- if there is no latency requirement, or there are very few services, we can choose either of them.
- if we are in micro-service environment, choose Saga
- if system is latency sensitive, TCC might be the better one.
Reproducibility
AKA: Event sourcing
There are 4 important terms in event sourcing:
- Command
- Event
- State
- State machine
Command
A command is the intended action from outside world. Request is a command.
Event
Command is the intention, event is the result.
Events represent the historical facts.
One key property of event: the event generation may contains randomness, same command might generate different events.
State
what will be changed when an event is applied.
State machine
A state machine drives event sourcing process, it has two major functions
- validate the command and generate events
- apply event to update state
Example
Here is an example showing how the event sourcing process works:
- state machine read commands from the command queue
- read the state from the database
- validate the command
- generate two events for each accounts
- read event queue
- apply the event by updating the balance in the DB
Advantage
With the event sourcing design, all changes are saved first as immutable history, DB are only used as an updated view of state, in our case, the account balance, at any given point in time.
We could always reconstruct historical balance states by replaying the events from the very beginning.
Scale up
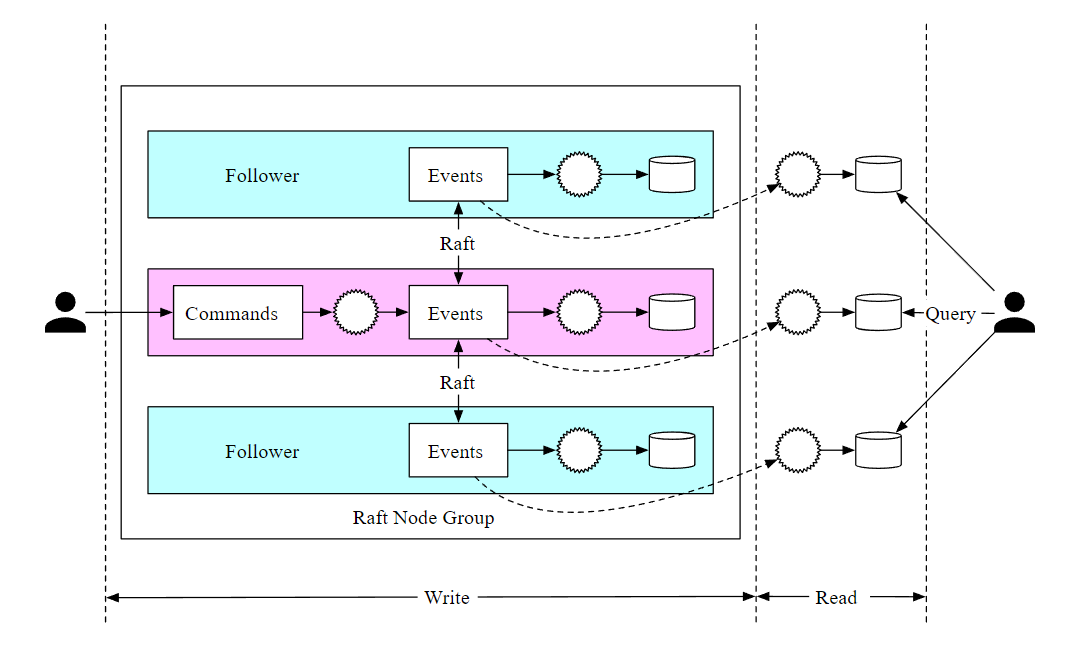
- Leader receive a command and save it into command queue
- then validate the command ,if valid, convert it into an event
- sync the event with followers
- follower apply the event and change the state.
Step3: Wrap up
In this article we went through the design of online digital wallet, where one account and send money to another account.
First we explore how to make sure the account balance is always correct by using distributed transaction, then we covered 3 types of solution: 2PC, TCC & Saga, also we introduce when to use what.
Then we encountered another problem which is reproducibility, we need to track the details of whole process, by introducing the event sourcing process, where we leverage state machine to update the state, and store the order of events.
Here are some of my takeaways:
- how to perform a distributed transaction.
- 2PC, TCC, Saga
- Event sourcing design
- command, events, state, state machine
- work flows
- advantage
- how the distributed transaction work combined with event sourcing design