
System Design Case Study: Ad Click Aggregation
One core benefit of online advertising is its measurability.
Digital advertising has a core process called Real-time Bidding (RTB)。
Based on ad click event aggregation result, campaign manager can control the budget or adjust bidding strategies.
Step1: Scope the problem
Some good questions to ask:
- what’s the data volume
- what’s the most important query to support
- what’s the latency requirement
Let’s assume the key features of our design are:
- aggregate the number of clicks of ad_id in last M minutes
- return top 100 most clicked ad_id in every minute
- support different aggregation filters based on attributes
Step2: High level design
API design
the purpose of API design is to have an agreement between client and server.
In our case, client is the dashboard user who runs queries against the aggregation service.
API1: aggregate the number of clicks of ad_id
GET /ad/ad_id/aggregated_counts?start=?&end=?&filter=?
API2: return top N most clicked ad_ids in a period
GET /ad/popular_ad?from=?&to=?&number=?&filter=?
Data Model
There are two ways to store data: raw data or aggregated data
It’s recommended to store both of them.
- We should store raw data, if something went wrong, we could use the raw data for debugging
- Aggregated data should be stored as well. Raw data size is huge, which makes the query very inefficient. To mitigate the problem, we can run queries on aggregated data.
- Raw data serves as back-up data and aggregated data serves as active data.
DB choice
some consideration before we choose the DB
- what does the data looks like?
- is the work flow read-heavy, write-heavy or both?
- is transaction support needed?
- Do query rely on many online analysis processing like SUM/COUNT?
Based on above consideration, here is our decision:
- nosql DB are more suitable because they are optimized for write and time-range queries, even though relational DB can do the job as well
- for aggregated data, it’s time-series in nature and workflow is both read and write heavy.
High Level Design
The input is the raw data (unbounded data stream), and the output is the aggregated result
Basic version
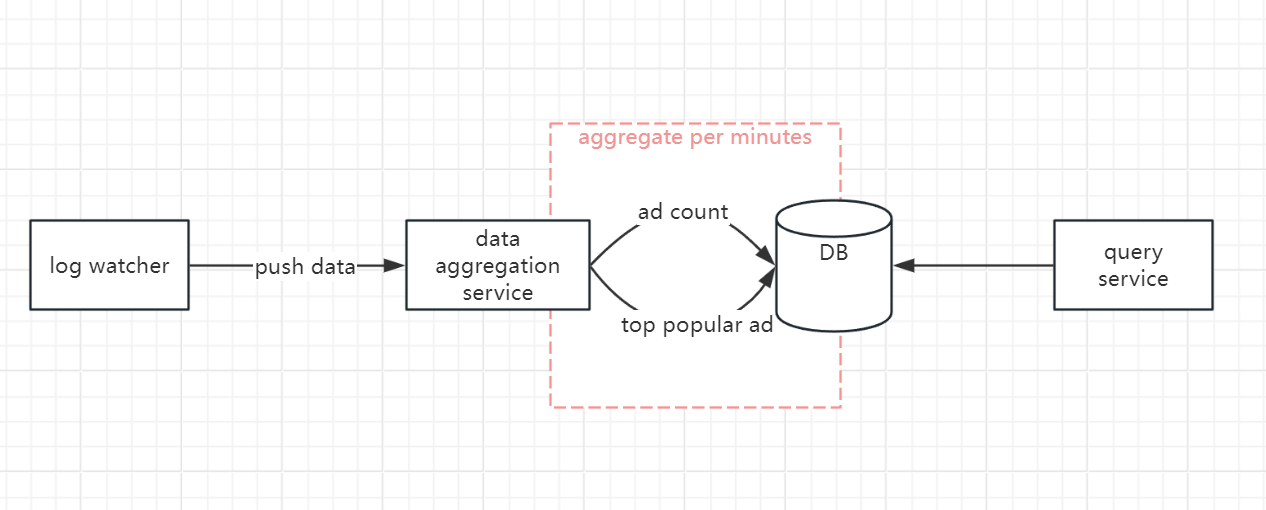
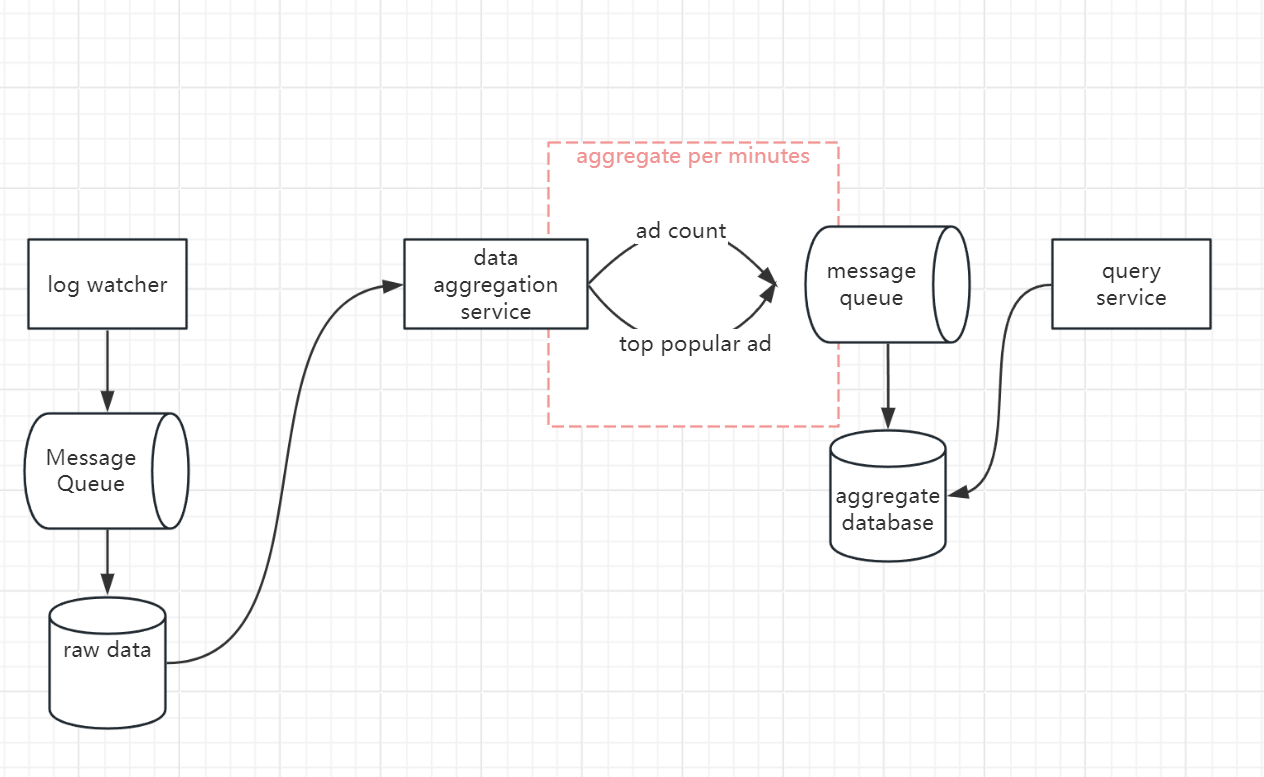
Improvement
We can introduce MQ to decouple services, so that producers & consumers can scale independently
Step3: Design deep dive
Aggregation Service
MapReduce framework is a good option for aggregating the ad-click events
Map Node
Map node reads data from a data source, then filters and transforms the data
Aggregate Node
this node counts ad_click event by ad_id in memory per minute.
Reduce Node
this node reduce aggregated results from all Aggregated Nodes to the final results, then find the most popular ads to return
Time stamp
There are two time stamp available in our system:
- event time: when an ad_click happens
- processing time: refers to the system time of aggregation server process the click event
Due to network an async environment, the gap between two time can be large.
There is no perfect solution, we need to consider the trade-offs
event-time is more accurate, and in our case, data accuracy is more important.
The mitigation is we use buffer time, i.e. we can extend the extra 15 seconds aggregation window. Even though, this solution cannot handle events that has long delays.
We can always correct the tiny bit of inaccuracy with end-of-day reconciliation
Window
There are several types of time window:
- fixed window
- sliding window
- session window etc.
Deduplication
It’s not easy to dedupe the data in large-scale system, how to achieve exactly-once processing is an advanced topic.
Reconciliation
Unlike the reconciliation in the banking industry, the results of ad click aggregation has no third party result to reconcile with.
What we can do is to sort the ad click events by event time in every partition at the end of day, using a batch job and reconciling with the real-time aggregation result.
Step4: Wrap Up
In this article, we go through the basic flow of ad-click aggregation service.
First we discussed the API design of system to reach the alignment between client and server.
Then we compare storing raw data or storing aggregated data, actually we should store both of them
We also discuss the details of aggregations service, essentially it’s a MapReduce framework, Mapper is responsible to fetch the raw data and standardize them, then pass data to Reducer which responsible for aggregate the data for each ad_id, and find out the most popular ad.
There are some detailed considerations in Aggregation service, for example, what time should we use? the time when event happens or when the event get processed in server?
How we define the window? should we use fixed window or sliding window?
Finally we discussed how to ensure the correctness of our real-time aggregation, at the end of day, we run a batch job on raw data again, then compare the real-time result with offline result to evaluate the accuracy.